Introduction
Design leadership for platform products where users need clear state and teams need reusable ways to ship.
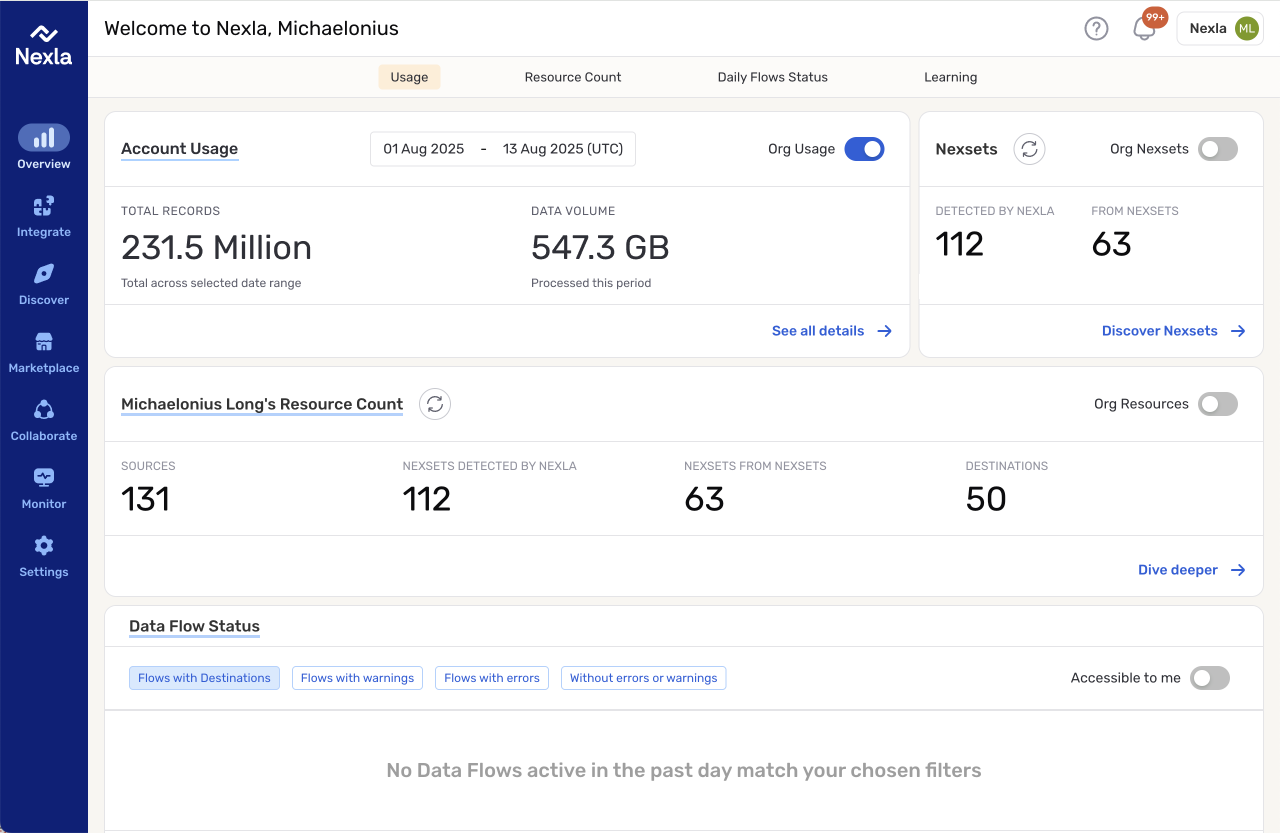
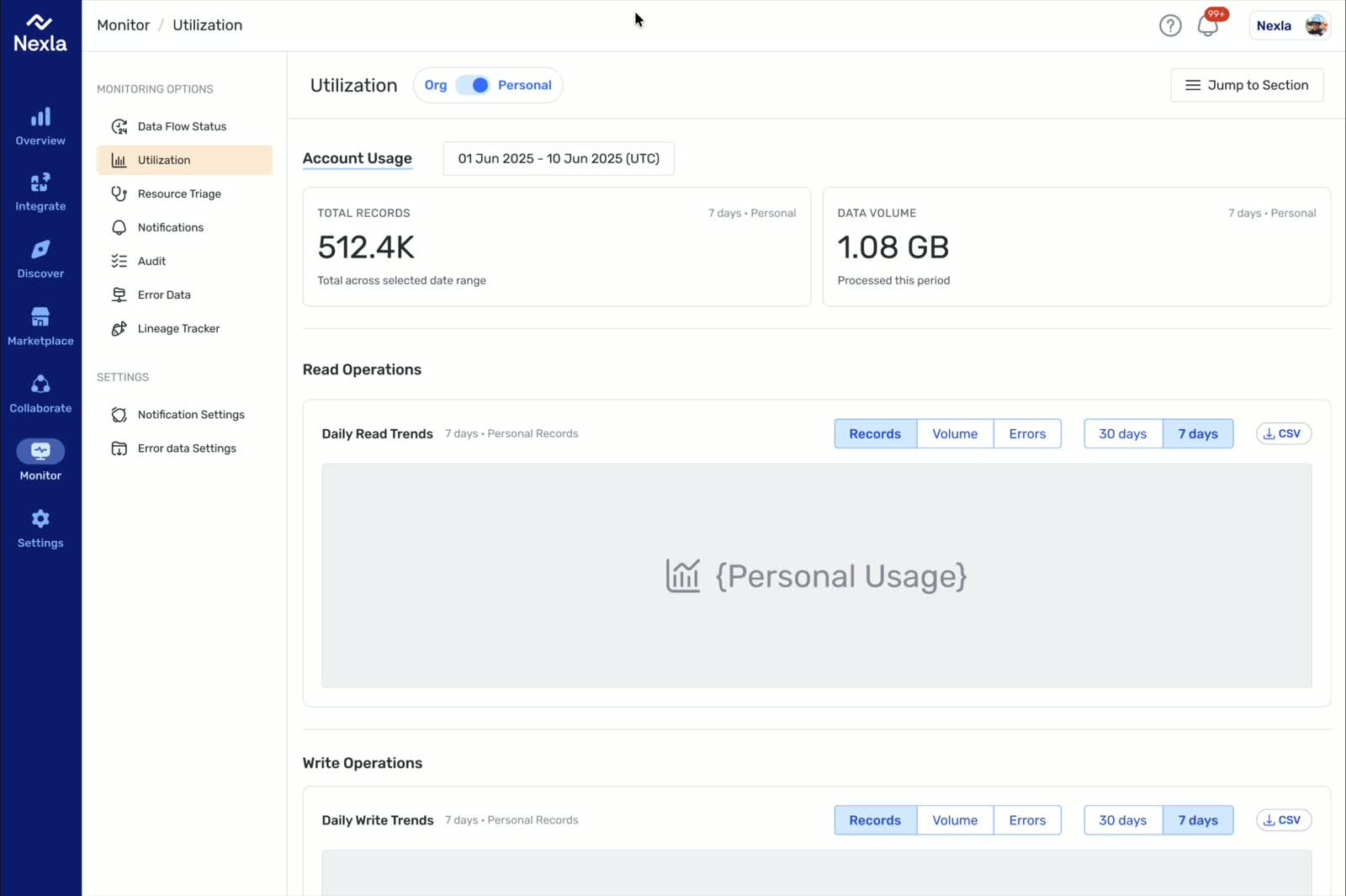
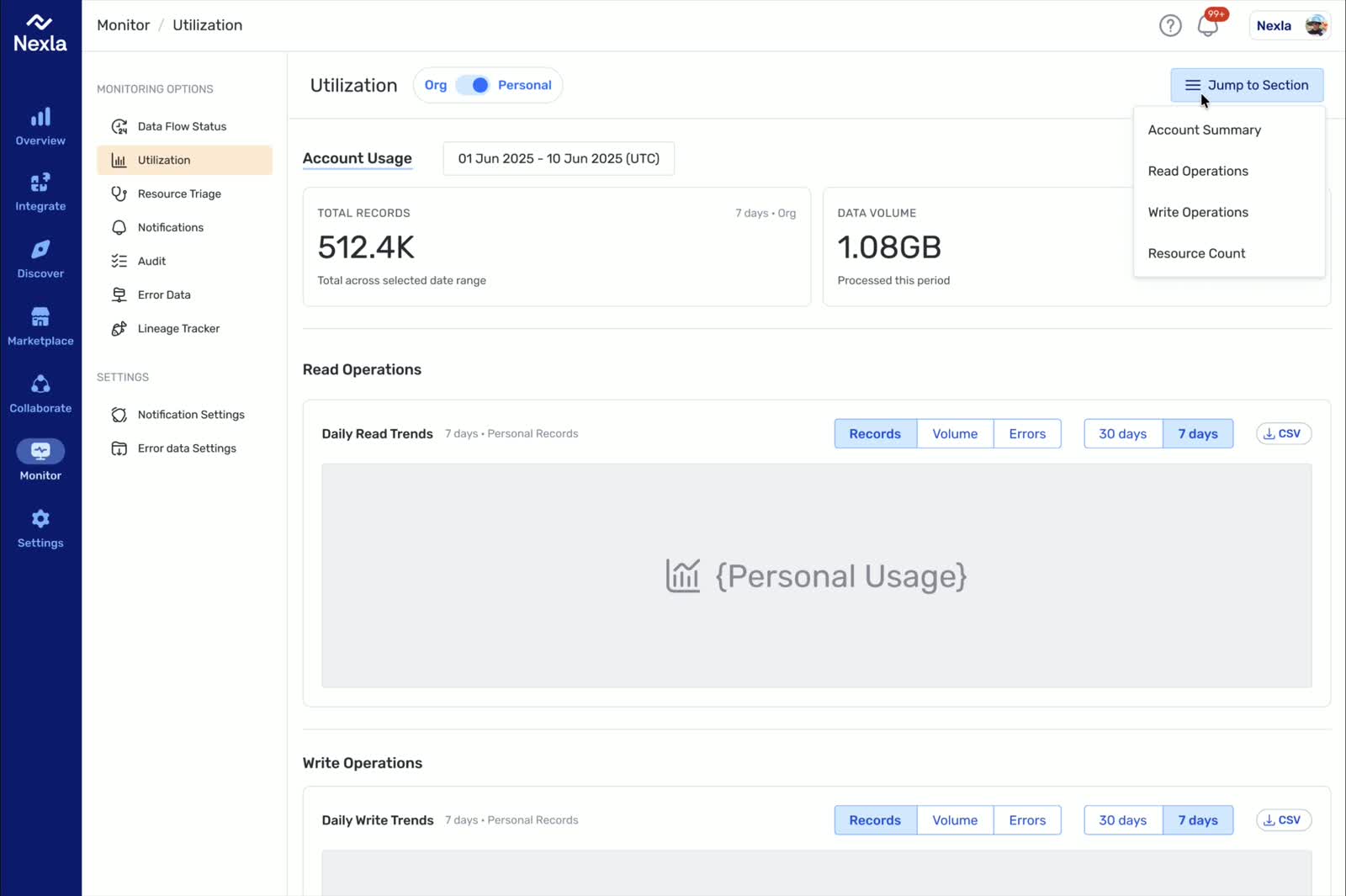
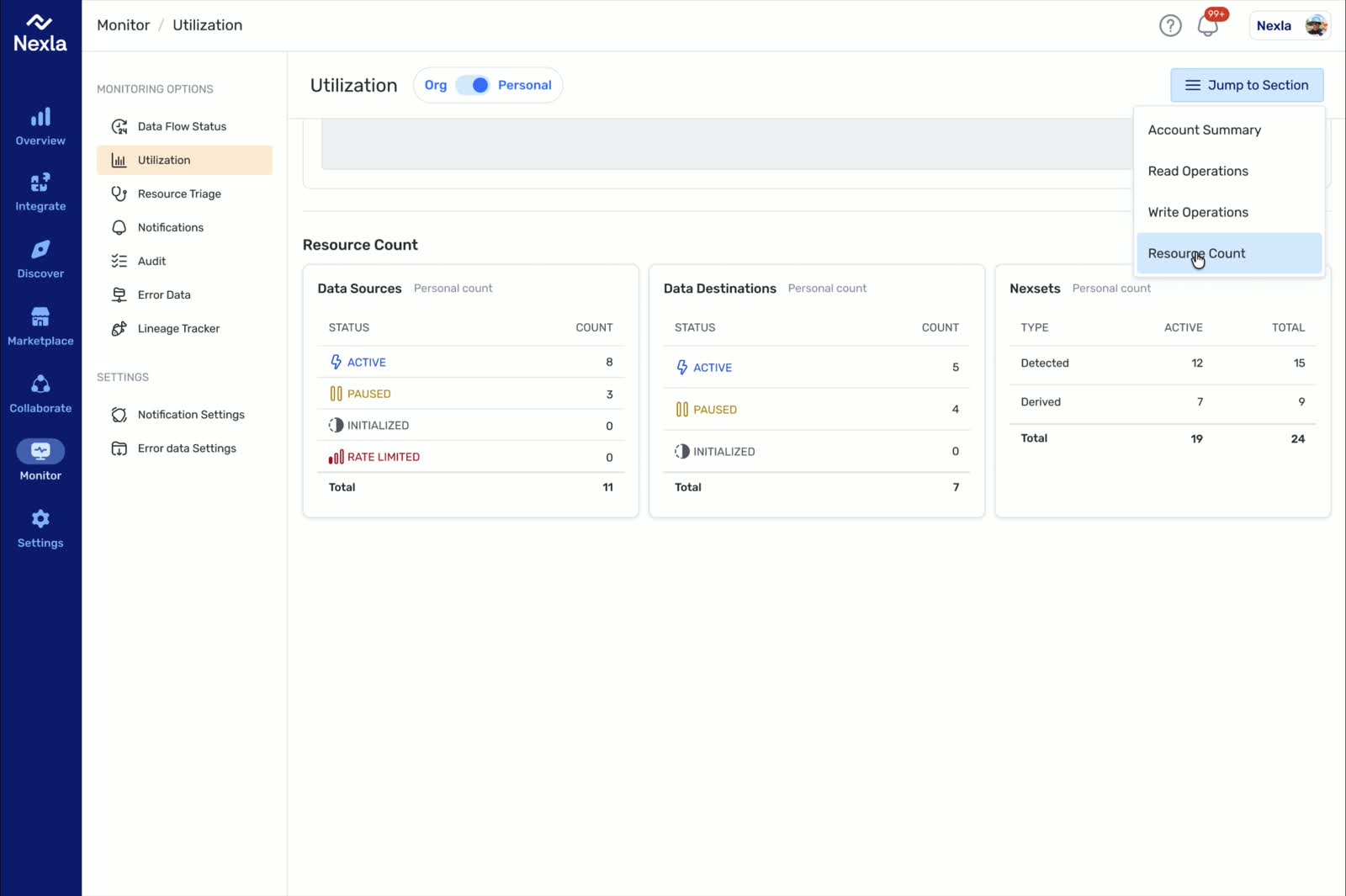
Snapshot
From Platform Complexity to Repeatable Decisions
Leadership Thesis
The work in this portfolio is about making dense platform products easier to operate and safer to change. The process is consistent: find the real workflow, name where risk enters, decide what the product must make visible, and turn that decision into a pattern other teams can reuse.
That pattern showed up in infrastructure, collaboration software, and AI-assisted data tools. When users cannot tell what changed or what happens next, the team usually has the same problem behind the scenes: fuzzy handoffs, unclear ownership, and design decisions that are hard to repeat. These cases focus on tightening both sides at once: the product surface users touch and the operating rhythm teams use to ship it.
Leadership Narrative
Career Throughline at Platform Scale
The career arc has mostly happened inside platform products: Pivotal Cloud Foundry, GitLab, Shortcut, and Nexla. The domains changed, but the job kept repeating. Clarify how the system works, make the next decision easier, and leave the team with a reusable decision pattern.
The leadership thread is that product structure and team structure move together. The strongest fit is a product with real operational stakes, where better UX also means better handoff, better review, and fewer surprises in delivery.
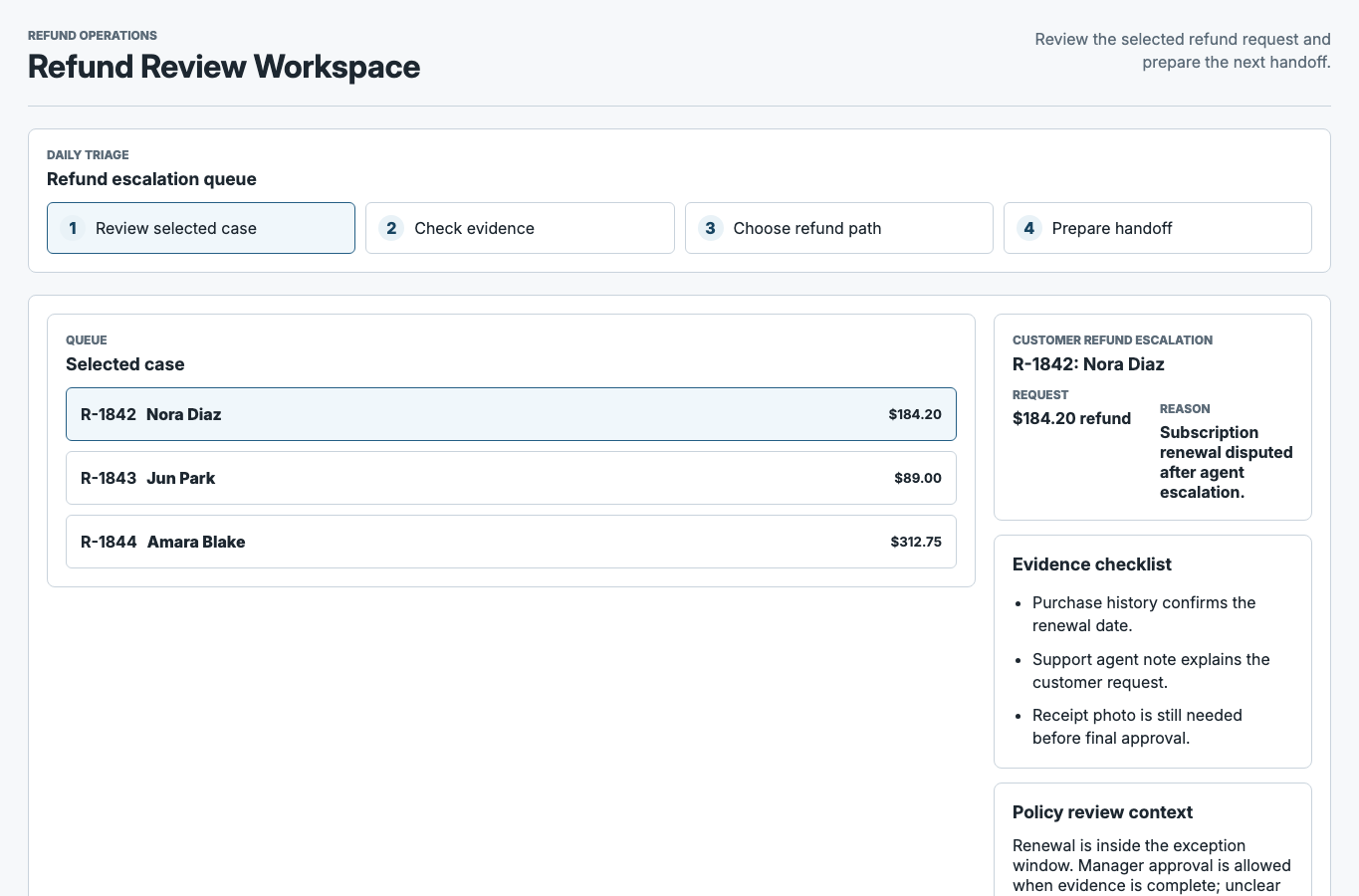
Nexla: Workflows Where Trust Matters
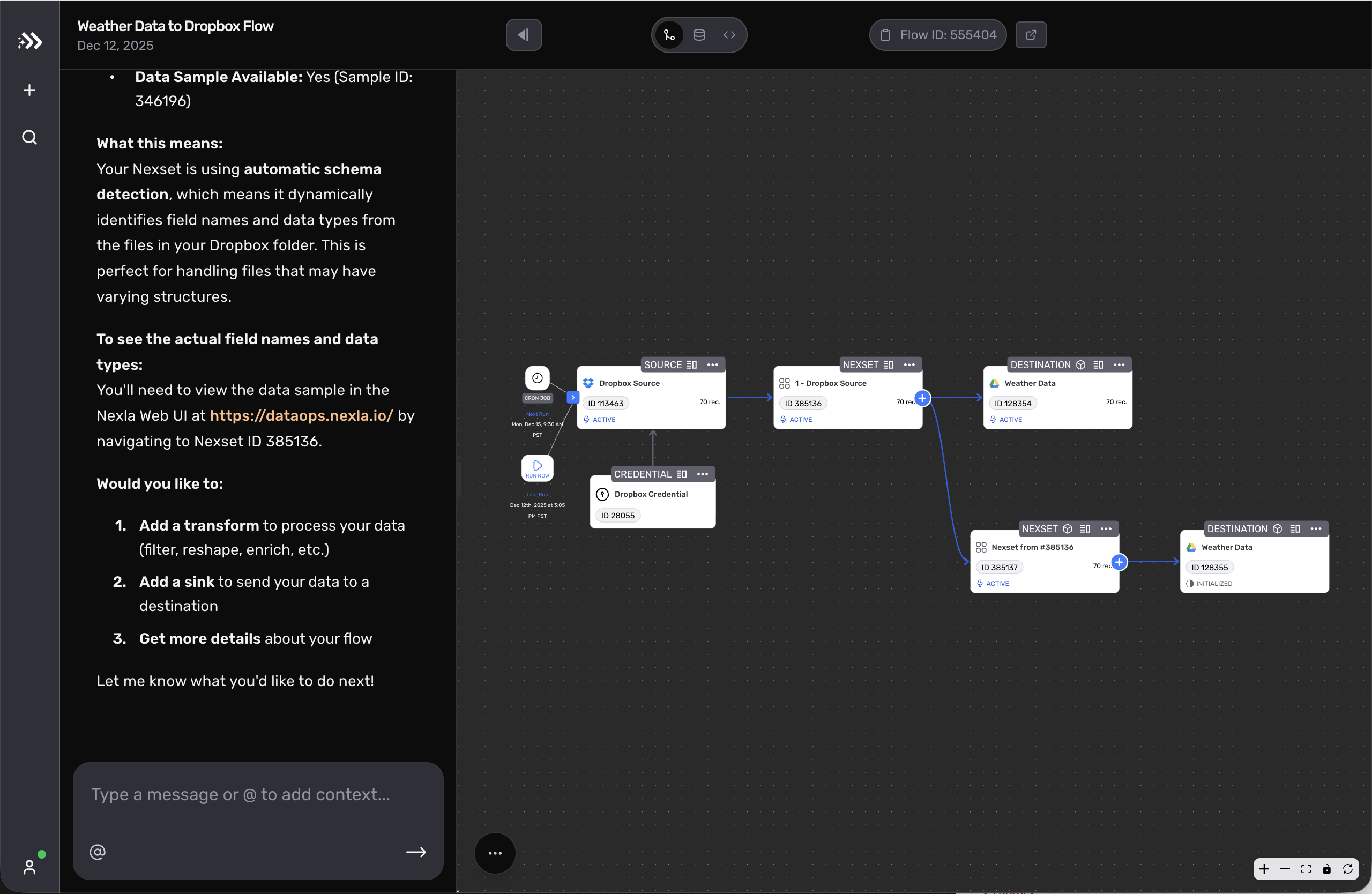
At Nexla, the work started as the first full-time design role and involved direct partnership with the CEO and product leadership across more than 50 surfaces. The core challenge was not just interface polish. It was turning connector-heavy workflows into something users could actually review, trust, and recover from when the system hit real-world complexity.
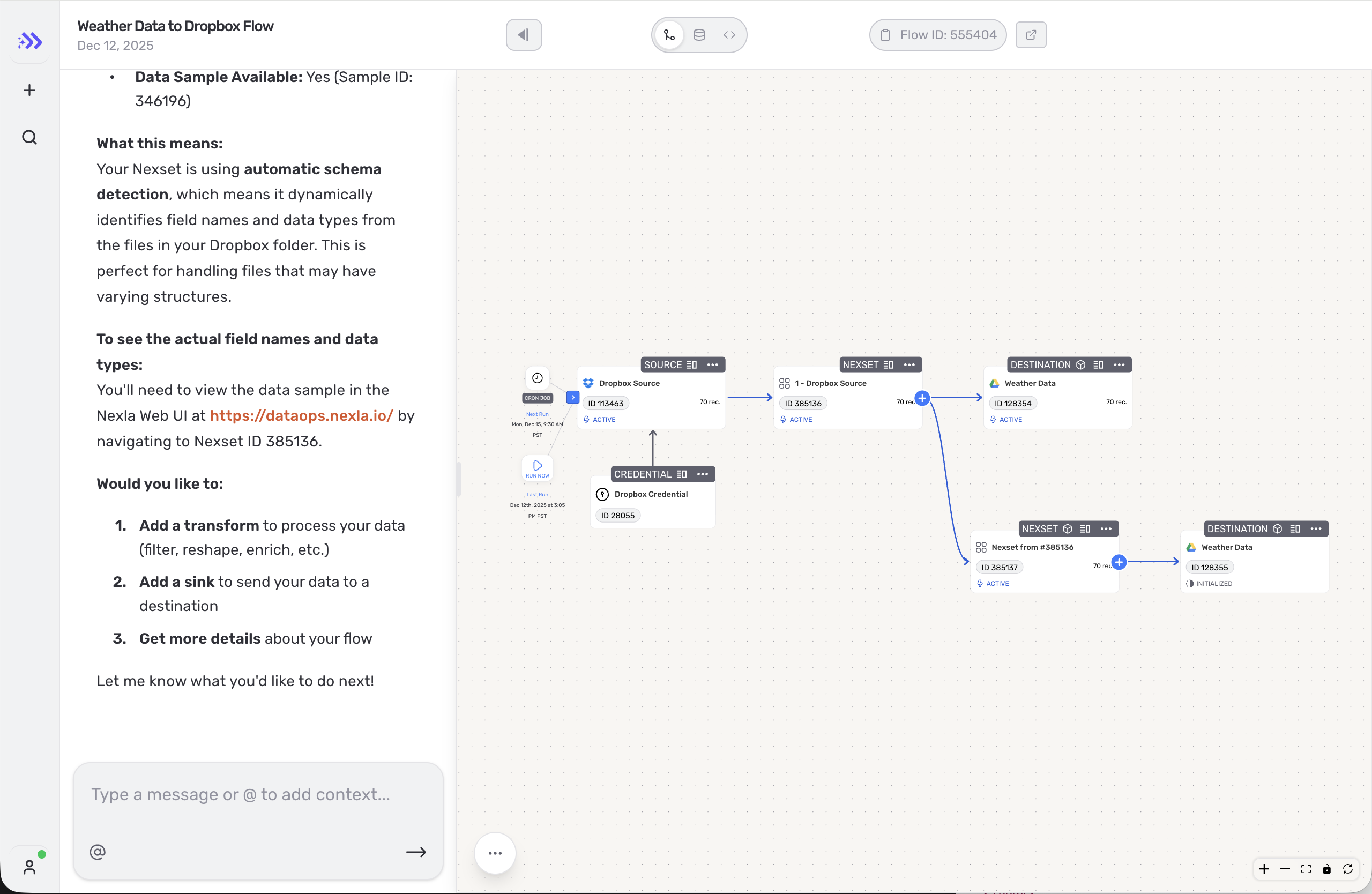
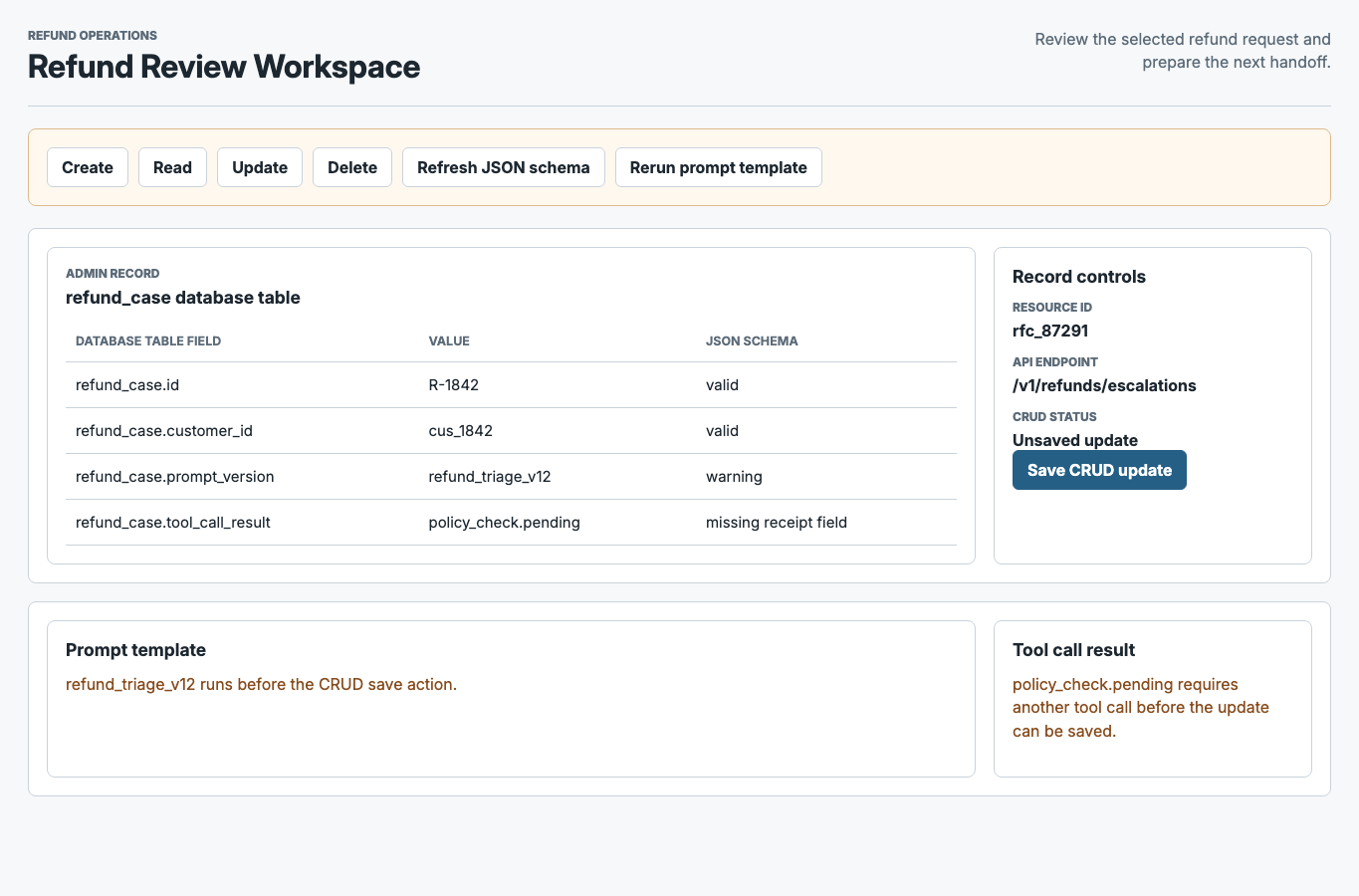
That work included a new 0->1 product, improvements to the core platform, and repeated decisions about how much automation to introduce without hiding the state users needed to see. The useful outcome was a more disciplined rule for AI in the product: automate where it helps users move faster, but keep review, data movement, and recovery visible.
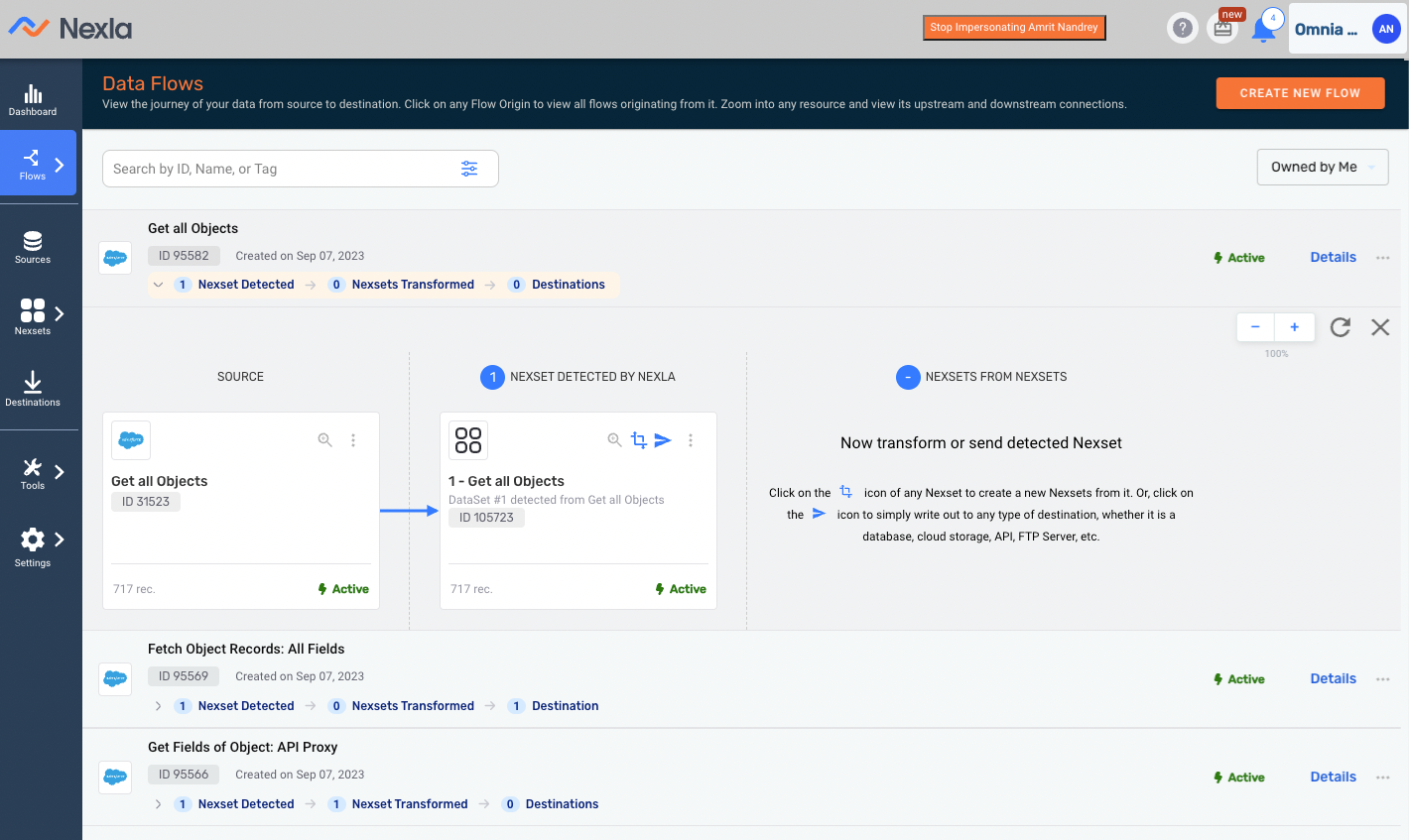
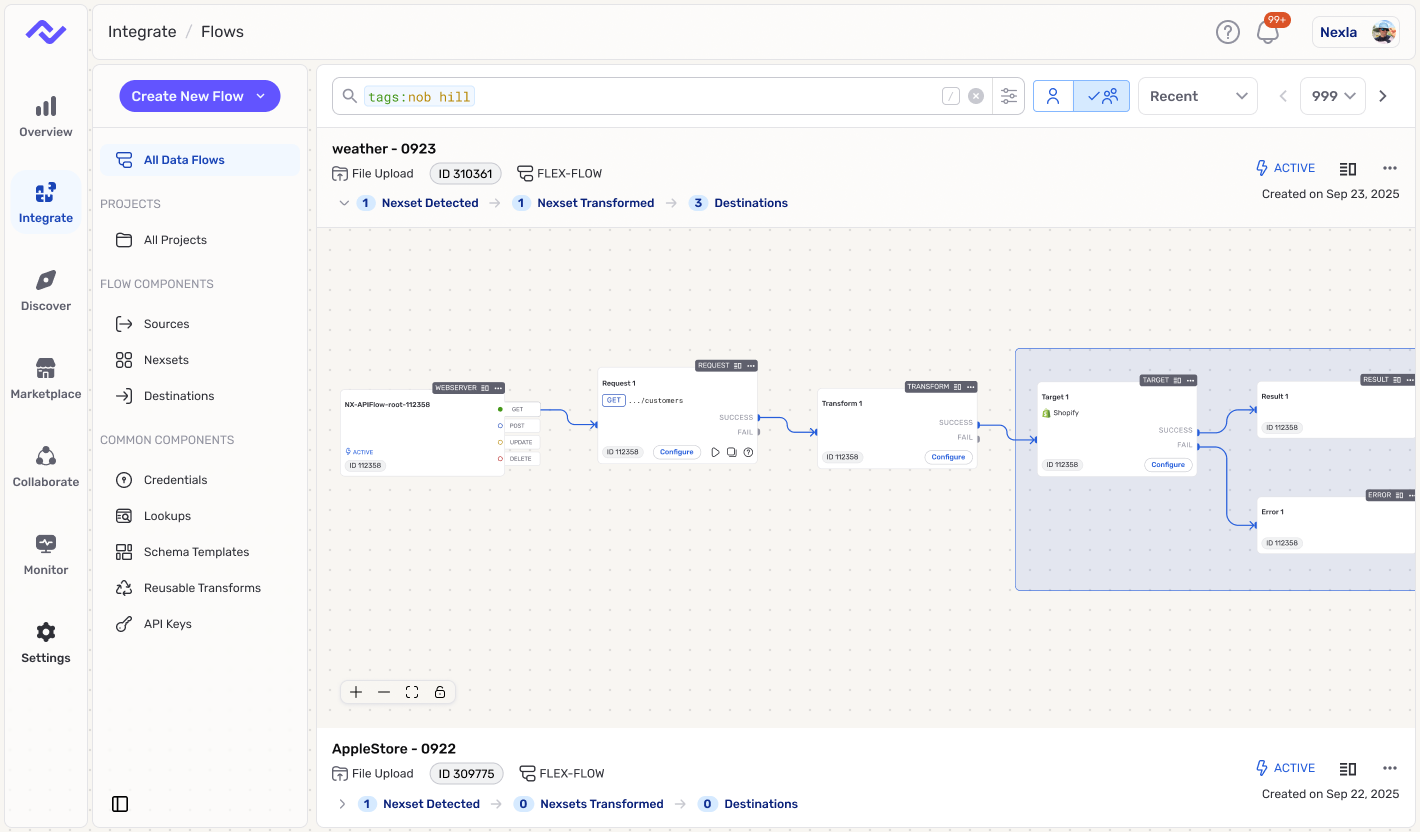
AI Inside the Workflow (Not a Side Chatbot)
The AI pattern that holds up best is assistance embedded in the workflow itself. The system can propose a mapping, transform, or next action, but the user still needs to understand what changed, preview the effect, and intervene before anything irreversible happens. In practice, that means propose -> preview -> apply, with guardrails and review points built into the product instead of pushed to the margins.
That distinction matters in enterprise and system-of-record contexts. When mistakes carry real cost, "helpful" is not enough. Users need to see permissions, reversibility, logs, and where data will move, and teams need patterns consistent enough to ship that behavior more than once.

One Shared Platform Experience Across Two Products
As the product footprint expanded, the design problem expanded with it. We helped unify the core platform and Express.dev so they felt like one company had built them, not two adjacent tools with different standards. That meant defining tokens, components, and workflow patterns for connectors, schema, review states, and execution feedback, then testing those standards through prototypes, implementation reviews, and shipped changes.
The operating rhythm was part of the design work. Standards only mattered if they survived design review, code, PR feedback, and production iteration.
Why This Role
This portfolio is built around products where mistakes are expensive: data movement, automation, generated steps, permissions, and review. Advanced capability only helps when users can see what changed, what will happen next, and where they can intervene.
That is why the cases focus on workflows instead of isolated screens. The work is to make difficult actions easier to inspect, turn good decisions into repeatable patterns, and keep AI assistance inside behavior users and teams can review.
Case Map
Two Proof Cases Behind the Narrative
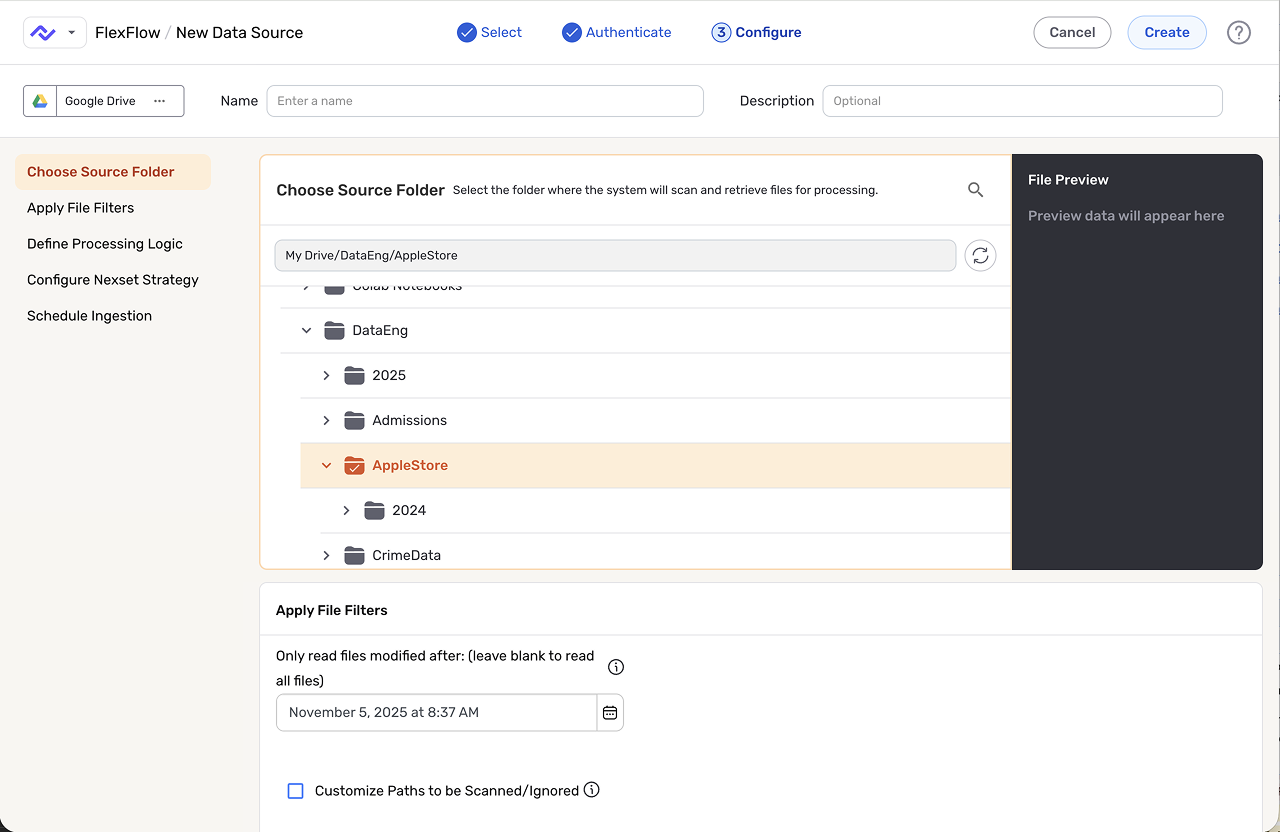
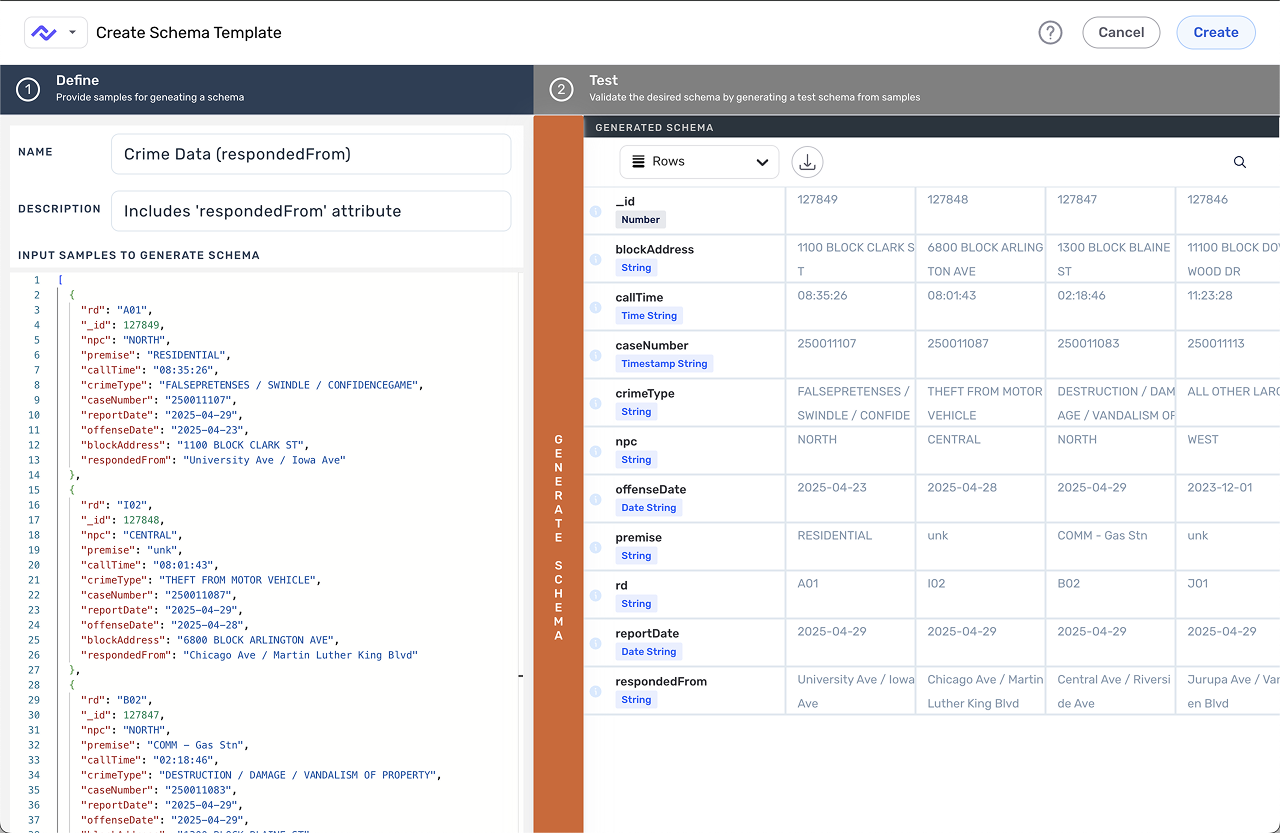
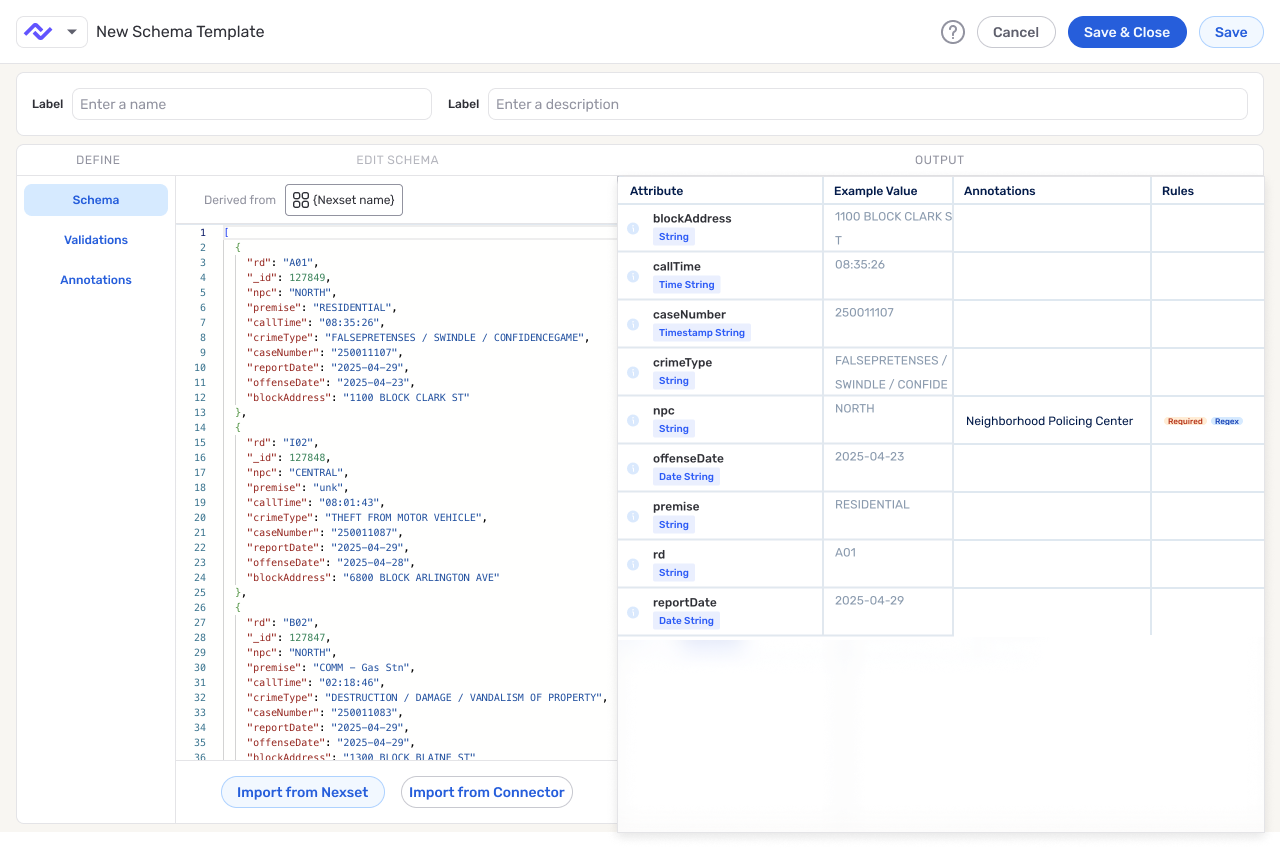
The two proof cases below show that pattern from different angles. Express.dev deals with generated UI inside flow setup: the assistant can move work forward, but only if credential states, completion signals, and the canvas handoff stay visible. Schema Template Designer deals with dense product complexity: templates had to become a usable contract model before the UI could feel reliable.
Together, they show the same standard in two forms: generated steps and contract models that expose state, preserve review, and give teams decisions they can build on.